Genes, proteins & biological function
Tutorial: Brief introduction to how life works
Watching the David Attenborough documentary series “Life on Earth” you cannot fail to be awestruck by the splendour and diversity of life on our plant, but it also begs the question: how did it all begin? Whilst there is currently no definitive answer to that question, science does at least provide an insight into the basic mechanics that allow life to exist and evolve. Fundamentally these mechanisms are easy to understand and have a certain beauty in their simplicity, though what they lead towards is exquisitely complex and mysterious. The aim of this tutorial is to explain these simple mechanisms to give you a better appreciation of how life at this microscopic level impacts our world in terms of things like cancer, genetic diseases, or the Covid-19 catastrophe.
If should take you about 30 minutes to read this post. You should have no difficulty understanding its content if you already know some school level science such as the role of molecules in chemistry and cells in biology. You will encounter a few technical terms, but they are introduced by explanations or have links to full descriptions.
- Genes
- Proteins
- Going from amino acids to biological function
- How genes sequences code for amino acid sequences
- How amino acid chains are assembled
- Folding of the amino acid chain
- Protein regulation
- Roles of proteins in biological processes
- Mutations
- Summary
- Further reading
- Related Posts
- References
Genes
Where are our genes found?
The fundamental unit of a living organism is the cell. The variety of life arises from the diversity of form and function of the cell which can exist independently as a single cell organism, or can be assembled into large multicellular organisms like ourselves. Given this diversity cells are remarkably similar in terms of their chemistry, the mechanisms they use to perform their functions, and their internal structures. The basic structure of a cell is shown in Figure 1. The ability to reproduce cells is a fundamental feature of all living organisms. Cell reproduction happens at the moment of conception, but it also happens in our bodies all the time. It involves the splitting of a cell to produce two new cells each with their own chemistry, internal mechanisms, and complete set of genetic instructions.
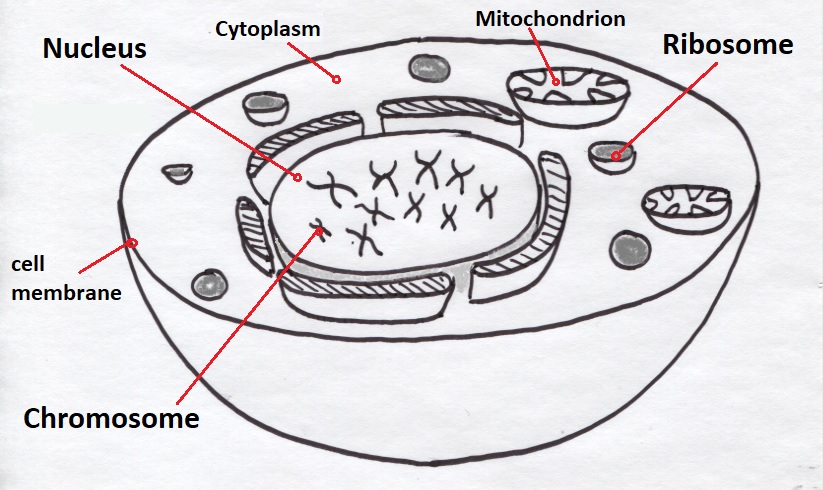
Figure 1: The basic structures common to most cells
Our ideas about what constitutes a life-form are heavily influenced by what we see as the basic properties of cells, specifically an ability to grow, reproduce, adapt, convert energy into a form it can use, maintain its internal environment, and respond to stimuli [Ref 1]. Each of these properties is key to understanding life as we know it, but let’s focus on the basic mechanism that underpins them all – the production of proteins from a set of genetic instructions called genes. All human genes are contained in our chromosomes which are stored in the nucleus of most cells.
Humans have 23 pairs of chromosomes which are identical in most of our cells. The key exception are the sex cells created in the testes (male) or ovaries (female) which contain a single set of 23 chromosomes. During conception the chromosomes from the male and female sex cells mix to produce a single cell with the normal 23 pairs which forms the basis of a new individual.
The role of DNA and chromosomes in storing genetic instructions
Each of our chromosomes contains a specific group of genes held within collections of Deoxyribonucleic acid (DNA) molecules. These DNA molecules are formed by linking together much smaller nucleotide molecules into long chains that coil around each other to form the well-know double helix structure shown in Figure 2. Each of these nucleotide molecules contain a phosphate backbone molecule which acts like the link in a chain as well as one of four base molecules which carry a code; adenine (A), guanine (G), cytosine (C) and thymine (T). Our genetic code is formed by sequences of these bases linked together in a DNA chain, like ACTGATTGT, though typically meaningful sequences are considerably longer.
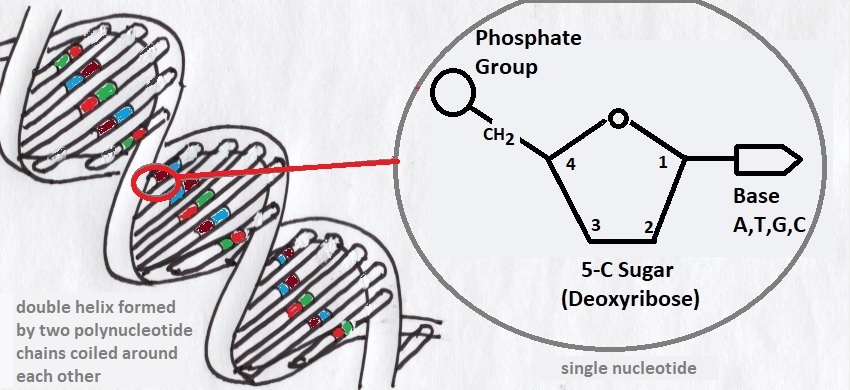
Figure 2: The helical structure of DNA first reported by Crick and Watson in 1953
The size of a DNA molecule is usually expressed in terms of the number of base-pairs (bp) it contains as DNA is actually formed from two complementary chains of nucleotides as shown in Figure 2. However as each chain contains the same genetic information, its length is often given in terms of the bases (b) in one chain.
Proteins
Going from amino acids to biological function
Amino acids are the building blocks of life in that they are the small molecules from which all proteins are assembled. A protein is simply a particular sequence of amino acids folded into a three dimensional molecular structure so it can interact with other biological molecules, including other proteins. Proteins provide all the cell’s various functions whether acting as enzymes to catalyse biochemical reactions, providing structural support, sending messages to other cells, or even orchestrating an immune response. Most cells are specialised to perform a particular function and collections of cells in a given organ collaborate to achieve a higher level function. For example, your heart contains muscle cells which produce proteins allowing them to contract. It also contains other specialised cells which produce proteins for sending messages to groups of nearby muscle cells telling them when to contract. Thus the various groups of cells in your heart with their different functions collaborate to pump blood around your body; a key biological function.
Our genetic instructions, or genes, tell a cell how to build proteins. A small protein might be defined by sequence of between 150 and 1,000 bases in a much longer chain of DNA. However, large proteins can be ten or twenty times as long. The human genome, our entire genetic code,is estimated to contain approximately 3 billion bases whereas E. coli bacteria has a genome with only approximately 4.6 million bases.
It is estimated that only 2% of the human genome contains code for producing useful proteins [Ref 2]. The remainder of our genome was once thought to consist mainly of what is termed junk DNA - sequences of codes the have become corrupted during our evolution so they no longer form useful proteins. However, it is now estimated that 80% of such areas have important functions such as regulating which proteins should be produced and in what circumstances.
How genes sequences code for amino acid sequences
Our genetic instructions, or genes, act like the sequence of binary codes that control a computer. In the same way that the values in a sequence of bits like 10000111 define a particular processor instruction such as ADD, the values in a gene sequence tell the cell how to assemble a sequence of amino acids into a chain. However, unlike computer code, there are only three types of instruction; start a chain, terminate (stop) a chain, and add a specified amino acid to the chain. Each instruction is defined by a series of three bases, called a codon. Therefore the gene sequence ‘ATG,GTT,AAA,GAC,TAA’ has five codons the first of which marks the start of a protein sequence and the last of which marks its end, whilst those in-between code for the amino acids in the chain, in this case Valine (GTT), Lysine (AAA) and Aspartic Acid (GAC).
A chain with at least 20 amino acids is needed to produce the smallest functional protein, but a chain can contain as many as 30,000 amino acids in the case of some of the longest proteins.
How amino acid chains are assembled
A process called transcription occurs in the nucleus and copies the part of DNA responsible for coding a specific protein into a new molecular chain of nucleotides called Ribonucleic Acid (RNA). The RNA molecule has a number of different roles, so in transcription it is called messenger RNA (mRNA) which reflects its function in passing the genetic code through the nucleus wall to cellular machinery responsible for making it into a protein; the Ribosome.
DNA and RNA have the same A,G, and C bases, but in RNA the base Uracil (U) replaces the DNA base thymine (T). The backbone of RNA is also formed from ribose instead of a deoxyribose sugar molecule and forms a single strand.
Protein synthesis happens in the cell’s Ribosomes and involves the construction of a chain of amino acids which then fold into a functioning protein. These amino acids circulate outside the nucleus in the cell’s cytoplasm. There are 20 standard types of amino acids in human cells. Some of them are are absorbed as part of the digestive process, but most are just fragments of old cell proteins which have been broken down by other cellular processes. Small molecules of RNA called transport RNA (tRNA) are also circulating in the cytoplasm and bind to particular amino acids depending upon the four possible values contained in the three bases in their anti-codon. In this way individual amino acids are carried to the Ribosome which is then responsible for assembling them in the order specified by the mRNA – a process called translation.
The creation of a chain of amino acids starts with mRNA binding to a particular subunit of the Ribosome called 40S. This subunit then works its way along the mRNA chain three nucleotides at a time until it identifies a start codon. At this point the Ribosome exposes the next codon of the mRNA so that binding can take place to a nearby tRNA molecule, but only one with a set of bases that are complementary to those of the exposed codon. In this way the first amino acid in the chain is precisely positioned by the bond between its tRNA and the exposed codon of the mRNA, as held by the Ribosome. The Ribosome then exposes the next codon of the mRNA and the process repeats, except this time a different subunit of the Ribosome called 60S orchestrates the bonding of its associated amino acid to the previous one, still held by its tRNA, so forming the first link in the chain. The tRNA molecule attached to the first amino acid is then released so it can be recycled. The Ribosome continues to crank through the mRNA in this manner, assembling the required chain of amino acids step by step, until it reaches a stop codon. At this point the chain of amino acids is complete so it is released by the Ribosome. The process of building an amino acid chain is summarised in Figure 3, but the animated video produced by the DNA Learning Centre brings it to life.
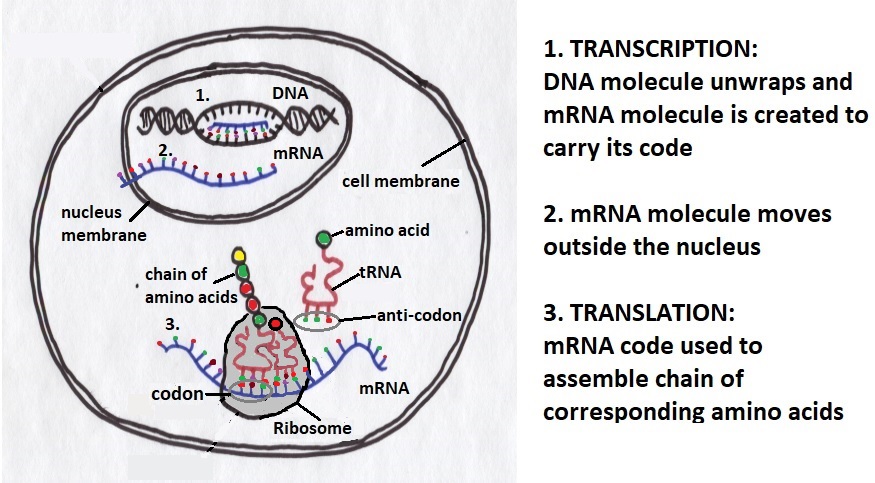
Figure 3: Assembly of amino acids by the Ribosome
Folding of the amino acid chain
A functioning protein is a three dimensional structure so the linear chain of amino acids needs to fold into a particular shape much like the way a cube is formed from a flat piece of paper as shown in Figure 4. Scientific knowledge about how proteins fold is limited so it is difficult to predict how a given amino acid sequence will form into a three dimensional structure with any degree of certainty. Accordingly it is usually necessary to work backwards and deduce structural information bit by bit by analysing samples of the final protein using techniques like x-ray diffraction or electron microscopy. These methods may take years to complete, but have great value as knowing the three dimensional structure of a protein is key to understanding its interaction with other biological molecules and so how it functions.
Figure 4: Folding of a two dimensional shape to form a three dimensional object
November 2020 Google’s DeepMind AI project claimed to reached a major milestone in terms of predicting the way any given amino acid sequence would fold into a protein [Ref 3]. This achievement may represent a major break-through as it opens the way for faster and better predictions of how a change in the amino acid sequence might alter the way the protein functions, allowing in turn improved assessments about the impact of mutations.
Protein regulation
The production of proteins in a cell is called gene expression and depends upon the needs of the cell. Some genes are always expressed, but others are switched-on and off allowing control of the timing, location and amount of a given protein being produced to change in response to environmental conditions. The mechanisms that regulate gene expression are not completely understood, but they have an important role in overall biological function in terms of ensuring that the correct types of proteins are present at the correct time and in sufficient numbers to allow the various chemical reactions in the cell to proceed. It is these reactions that provide the basis of most biological processes.
Roles of proteins in biological processes
Biological processes usually involve making some form of chemical transformation to a molecule, called the substrate. Typically this transformation of the substrate is performed in a number of steps to form what is known as a metabolic pathway. Each step, like splitting the substrate in two or bonding it to another molecule, performs a small chemical reaction to prepare it for the next step.
Certain types of proteins called enzymes have an important role in these chemical reactions as their amino acids are folded in such a way as to facilitate the formation of chemical bonds between a part called its active site and a particular part of the substrate called a binding site. The enzyme might then bind to another molecule’s binding site thereby bringing it close to the substrate to make the formation of a chemical bond between the two of them more likely as shown in Figure 5. Once the enzyme has performed its role as matchmaker it detaches so can be recycled and do the same again with another substrate. Therefore an enzyme can be described as a catalyst. It speeds-up reactions between a substrate and its associated molecules by bring them together in a suitable orientation; something that might take a considerable time if left solely to chance.
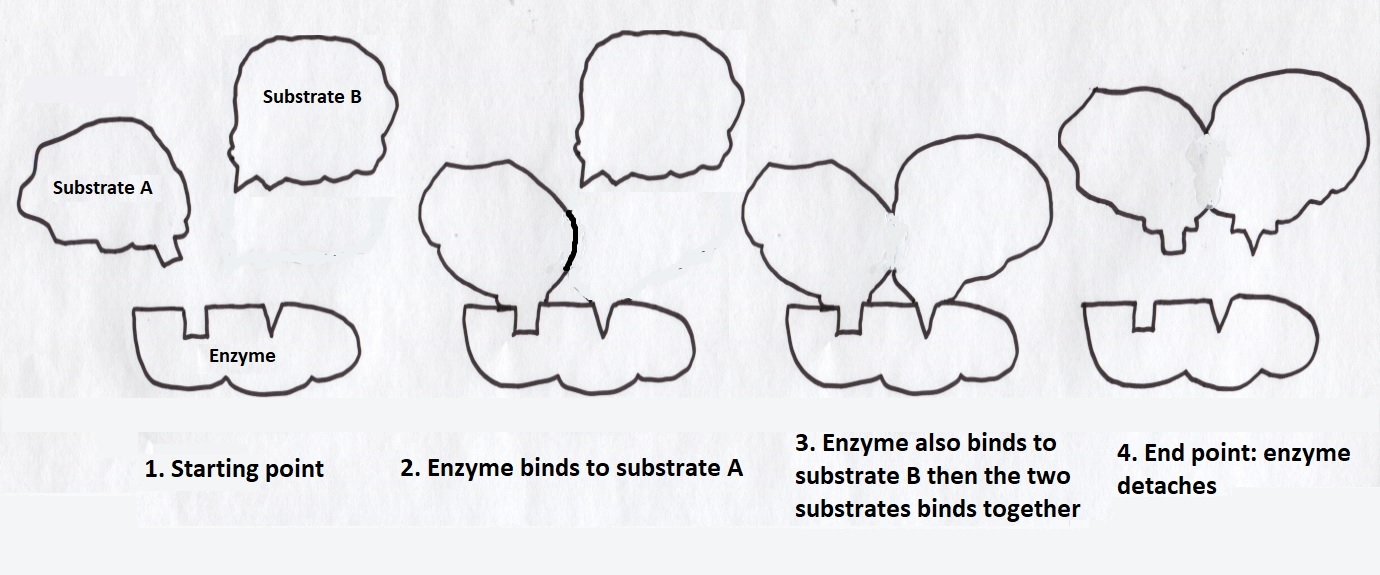
Figure 5: Enzyme binds to two molecules to help them react together
An enzyme can also act in other ways. For example, it can attach to binding site in the substrate and then brake some of its nearby chemical bonds so helping it to split in two. There are large numbers of different types of enzymes and reactions in metabolic pathways are typically controlled by activating or deactivating them. Most of the major metabolic pathways, like those concerned with energy production, are well understood. However, many other pathways are still largely unknown. The dynamic interaction between pathways to achieve high level biological function are even less understood; similarly the mechanisms that govern when particular pathways are activated and the cell signalling that coordinates them.
Mutations
Impact of protein mutations
The construction of a chain of amino acids from a DNA template is not an error free process, so sometimes the chain contains an error (mutation) which causes it to fold into a slightly different three dimensional structure. This may result in the production of a protein with different properties. For example, a protein that acts as an enzyme with a small mutation in its active site may bond less easily with the substrate’s binding site because the change in shape causes them to fit together less well, much like small damage to a key just makes it more difficult for you to activate its lock. The change may even be sufficient to stop it catalysing the chemical reaction completely. However, a mutation in an enzyme occasionally has the reverse effect and makes bonding easier. This may improve the efficiency of the associated biological process and thereby confer significant advantage to the organism. Consequently some mutations in enzymes and other proteins may help an organism to become better adapted to its environment. For this reason a certain rate of mutation is beneficial, but it must not be so high as to cause a chaotic effect in terms of protein function.
Protein synthesis in the Ribosome may be companied by error correcting mechanisms like proof reading which correct errors made during assembly of the amino acid chain. This makes the protein more resilient to mutation and so more stable. The nature of the genetic code itself also acts to reduce the rate at which proteins mutate.
Genetic code mutations
Mutations in an amino acid chain are usually the result of the incorrect bonding of nucleotides during the copying of DNA to mRNA which cause errors in the genetic code arriving at the Ribosome. However there is some tolerance for such errors as different codon values may code for the same amino acid so allowing for some degree of self-correction. This replication happens because there are more permutations for the value of a codon (64) than the number of amino acids (20) and the required control instructions (start, stop). Therefore, given both GUU and GUC code for the same amino acid (Valine), a mutation of U to a C in the third base of the codon GUU will self-correct as both GUU and GUC code for Valine. Most amino acids have at least one such replicated nucleotide code and some have as many as four. In addition there are also replications for the stop instruction, though not for the start instruction which is always AUG.
Despite the self-correcting nature of the code, some errors still persist. They have three basic forms: a deletion whereby a nucleotide is missed from the sequence, an insertion whereby additional nucleotides are added into the sequence, and a substitution whereby or one nucleotide may take the place of another. These types of errors can be further described in terms of:
- Loss or gain of a single nucleotide in a coding region means each following nucleotide ends-up in the wrong codon. This is called a framing error. For example, in sequence AUG,GUU,AAA the loss of the first A in the first codon of the means the first codon changes to UGG and the second becomes UUA, etc.
- Substitution of a single nucleotide in a coding region means the associated codon may code for a different amino acid; a missense mutation. For example a substitution of the middle base adenine (A) for guanine (G) in the codon AAA would make it code for Arginine (AGA) rather than for Lysine (AAA). However, due to the self-correcting nature of the code the change of a single nucleotide may still code for the same amino acid – this is called a synonymous mutation.
- Gain of a start/stop codon by substitution of one or more nucleotides to form a start (AUG), or stop codon (UAA, UAG, UGA) are usually significant. A gained start codon will prematurely initiate a new coding region so the following codons code for an amino acid sequence that will be prepended to the usual sequence for the protein. Conversely a gained stop codon in an existing coding region will truncate the amino acid synthesis for the protein at that point.
- Loss of a start/stop codon by substitution or loss of one or more nucleotides in the codon that forms a start or stop codon typically cause major damage to the protein. A lost start codon prevents the protein from being synthesised, whereas a lost stop codon will cause protein synthesis to continue until the next start codon.
- Loss or gain of a group of three nucleotides will result in the removal or addition of one or more amino acids to the protein being synthesised. Sometimes quite long strings of amino acids are lost or gained resulting in significant changes in protein function.
- Mutation in a sequence that doesn’t code for a protein will clearly not alter any protein, though it may change protein regulation.
The impact of a genetic mutation on the functioning of a protein depends on where it occurs and what form it takes. For example, the gain of a stop codon in the middle of the coding sequence associated with the creation of an enzyme’s active site may well cause a complete loss of function by preventing the site from achieving the shape it needs to fit into the substrate’s binding site. However, a minor mutation like the loss of an amino acid in the same place may only slightly change the shape of the active site making it fit less perfectly so making the the enzyme less effective, though it could equally improve the fit and have the reverse effect. The majority of genetic mutations either have no effect on the final protein because they occur in a coding region that is unimportant for its function, or have some catastrophic effect causing a complete loss of function. It is only the few mutations that improve the functioning of the final protein that have evolutionary significance and even then only if they can be passed to the next generation.
A virus cannot be called an organism as it lacks some of the properties that define a cell. However, it is able to hijack mechanisms in its host cells in order to replicate and in this way its genetic mutations are passed to subsequent generations. Therefore a mutation that confers some significant advantage, like a change in a protein which allows it to enter host cells more easily, will lead to it becoming more dominant in a local population by out-competing forms of the virus that do not have the mutation.
Mutational timescales and evolution
The common chemistry and structure of cells so far discovered in all organisms of whatever lineage strongly suggests that they have all evolved from some chance alignment of amino acids from which self-replicating proteins developed into the very first cell on Earth [Ref 4]. This evolution has taken a very long time, for the Earth is estimated to be 4.54 billion years old and it is thought that the first single-celled organisms started to emerge about 3.5 billion years ago. It wasn’t until about 600 million years ago that simple multicellular organisms started to appear. Going back 210 million years the earliest mammals arrived and they were followed by mankind’s oldest relatives, the hominids, which arrived 4.4 million years ago. The earliest signs of our species, Homo sapiens, date back just 300,000 years. Therefore it might be concluded that evolution has lead to the development of complexity which has grown exponentially as simple structures have become more ever more complex to better exploit their environment.
Viruses are very simple in terms of their structure, but can replicate and spread amongst host organisms very quickly. For example the new strain of the coronavirus, SARS-Cov-2, evolved and within a year spread throughout the world infecting almost 100 million people.
Summary
Science has come a long way since the structure of DNA was reported by Crick and Watson in 1953, but is still far from being able to use the information it contains in order to master disease, or exercise control over life with any certainty of the outcome. However, the basic building blocks of life, amino acids, have been studied in great detail and are well understood. Similarly the way in which amino acids are assembled into long chains following a particular sequence of types according to codes formed in our genes is no longer a mystery due to advances in Genomics.
Unfortunately the folding of amino acid chains into functional proteins is less well understood, so too is the way such proteins orchestrate many higher level biological functions. This is because biological function depends on the three dimensional structure of the protein which is generally difficult to predict from a given amino acid sequence. Furthermore, even if it is known how the structure of a protein impacts a particular chemical reaction, knowledge about the role of this reaction in a particular metabolic pathway may be incomplete, as may the dynamic mechanisms required for the interactions of such pathways to achieve a given biological function. Therefore, at present, science cannot predict with any certainty the effect of most changes in the amino acid sequence of a protein.
In time science will develop the sort of complex computer models necessary to calculate the behaviour of proteins from their amino acid sequences and their role in the dynamic metabolic pathways that result in higher level biological function. This will allow the rapid and reliable prediction of the impact of genetic mutations in silico leading to a transformation in our understanding of many diseases as well as the development of much better treatments. In the meantime science will continue to work in vitro to look at changes in biological function and work backwards to determine the amino acid changes that may have caused it; something that requires extensive and time consuming laboratory study. However, it is these same methods that have allowed us to understand how life works, even if we don’t yet understand its ultimate cause and reason.
If you found this post useful please help raise my profile by providing a link on your social media account; just click the buttons at the top of the page. You can also add a comment or contact me by email, but I can’t promise to respond immediately.
Further reading
Popular Science Books
The following books provide more detail about some of the topics discussed in this post and are aimed at a general audience:
- DNA The Secret of Life; James D. Watson [Ref 5]
- Gene Machine: The Race to Decipher the Secrets of the Ribosome; Ramakrishnan V. [ref 6]
Text Books
People studying life sciences or medicine may find the following books useful:
- Essential Cell Biology; Alberts B, Hopkin K, et al [ref 7]
- Genomes 4; Brown TA [ref 8]
Internet Sources
The internet provides a vast amount of information about the topics discussed in this post, but the following are particularly recommended:
- Berg JM, Tymoczko JL, Stryer L. Amino Acids Are Encoded by Groups of Three Bases Starting from a Fixed Point. Biochemistry 5th edition [Internet]. 2002. Available from: https://www.ncbi.nlm.nih.gov/books/NBK22358/
- Cooper GM. The Origin and Evolution of Cells. The Cell: A Molecular Approach 2nd edition [Internet]. 2000 [cited 2021 Jan 14]; Available from: https://www.ncbi.nlm.nih.gov/books/NBK9841/
- Human Genome Project FAQ [Internet]. Genome.gov. Available from: https://www.genome.gov/human-genome-project/Completion-FAQ
Related Posts
This tutorial provides an introduction to the following posts:
References
The following sources of information are referenced in this post:
- Alberts B, Hopkin K, Johnson AD, Morgan D, Raff M. Essential Cell Biology. Fifth-International Student Edition. New York (NY): W. W. Norton & Company; 2019. 750 p.https://www.amazon.co.uk/Essential-Cell-Biology-Bruce-Alberts/dp/0393680398
- Elkon R, Agami R. Characterization of noncoding regulatory DNA in the human genome. Nature Biotechnology. 2017 Aug;35(8):732–46. Available from https://www.nature.com/articles/nbt.3863
- Timmer J. DeepMind AI handles protein folding, which humbled previous software [Internet]. Ars Technica. 2020. Available from: https://arstechnica.com/science/2020/11/deepmind-ai-handles-protein-folding-which-humbled-previous-software/
- NASA Astrobiology [Internet]. Available from: https://astrobiology.nasa.gov/news/how-did-multicellular-life-evolve/
- James D. Watson DNA The Secret of Life by Watson, ON Apr-01-2004, Paperback. Cornerstone; 2004 Available from https://www.amazon.co.uk/Watson-Secret-Author-Apr-01-2004-Paperback/dp/B00NBMD4LQ
- Ramakrishnan V. Gene Machine: The Race to Decipher the Secrets of the Ribosome. Oneworld Publications; 2019. 288 p. Available from https://www.amazon.co.uk/Gene-Machine-Decipher-Secrets-Ribosome/dp/1786076713
- lberts B, Hopkin K, Johnson AD, Morgan D, Raff M. Essential Cell Biology. Fifth-International Student Edition. New York: W. W. Norton & Company; 2019. 750 p Available from: https://www.amazon.co.uk/Essential-Cell-Biology-Bruce-Alberts/dp/0393680398/.
- Brown TA. Genomes 4. 4th edition. New York, NY: Garland Science; 2017. 544 p. Available from https://www.amazon.co.uk/Genomes-4-T-Brown/dp/081534508
Comments
Для надежной работы в течение многих лет монтаж системы водоснабжения должен быть защищен гарантийным и послегарантийным сервисом. Монтажные работы выполняют сертифицированные специалисты нашей компании - <a href=https://наро-фоминск.водоснабжение-дома.рус/>https://наро-фоминск.водоснабжение-дома.рус/</a>, которые прошли качественное обучение и периодически повышают квалификацию. Личный сектор пользуется как центральным водоснабжением, так и автономным (колодец или скважина). Наша компания специализируется на установке систем водоснабжения дома с нуля "под ключ" с источником водоснабжения - колодца, скважины или центрального водопровода. <a href=https://ibb.co/2t5qMdF><img src="https://i.ibb.co/xj3hg62/nastol-com-ua-216257.jpg"></a> Преимущества автономного водоснабжения: - практически неограниченное и стабильное водопотребление; - возможность использования собственным режимом водоподготовки (для оптимального коллоидного состава воды необходим ее регулярный расход); - отсутствие абон платы (правда, если вы пользуетесь общим канализационным коллектором, придется платить за удаление стоков). Наша компания предлагает Вам профессиональную помощь и полный спектр услуг в устройстве как всей водопроводной системы в Вашем доме, так и ее отдельных видов работ, с использованием современных материалов и оборудования. Все работы выполняются исключительно нашими специалистами, с опытом работы более 10 лет в сантехнике. Мы закрываем 100% объёмов по всем видам работ. Подробнее на сайте компании: <a href=https://наро-фоминск.водоснабжение-дома.рус/vodosnabzhenie-iz-tsentralnogo-vodoprovoda/>Водоснабжение из центрального водопровода</a>, <a href=https://наро-фоминск.водоснабжение-дома.рус/vodosnabzhenie-doma-iz-skvazhiny/>Водоснабжение дома из скважины в Наро-Фоминске</a>.
BiolKiyyt